Kubernetes node affinity: examples & instructions
Kubernetes node affinity
Pod scheduling is one of the most important aspects of Kubernetes cluster management. How pods are distributed across nodes directly impacts performance and resource utilization. Kubernetes node affinity is an advanced scheduling feature that helps administrators optimize the distribution of pods across a cluster.
This article will review scheduling basics, Kubernetes node affinity and anti-affinity, pod affinity and anti-affinity, and provide practical examples to help you get comfortable using this cluster scheduling feature.
What is scheduling in Kubernetes?
Kubernetes scheduling is the process of selecting a suitable node to run pods.
To understand Kubernetes node affinity, you first need to understand the basics of Kubernetes scheduling created to automate the process of pod placement. Kube-scheduler is the default scheduler in K8s, but administrators can use custom schedulers, too.
The most basic approach to scheduling is through the nodeSelector available in Kubernetes since version 1.0. With nodeSelector, users can define label-key value pairs in nodes and use these labels to match when scheduling pods.
You can specify the nodeSelector in the PodSpec using a key-value pair. If the key-value pair matches exactly the label defined in the node, the pod will get matched to the specific node. You can use the following command to add labels to the nodes.
kubectl label nodes <node-name> <key>=<value>
The PodSpec for the nodeSelector is as follows.
spec:
containers:
- name: nginx
image: nginx
nodeSelector:
<key>: <value>
Using the nodeSelector is the recommended way to match pods with nodes for simple use cases in small Kubernetes clusters. However, this method quickly becomes inadequate to facilitate complex use cases and larger K8s clusters. With Kubernetes affinity, administrators gain greater control over the pod scheduling process.
What are Kubernetes affinity and anti-affinity?
The affinity and anti-affinity features in Kubernetes provide administrators with more granular scheduling functionality.
With affinity and anti-affinity, administrators can:
- Define rules, including conditions with logical operators.
- Create “preferred” and “required” rules for a greater variety of matching conditions.
- Match labels of pods running within nodes and determine the scheduling location of new pods.
There are two types of affinity: Kubernetes node affinity and Kubernetes pod affinity. Since the naming may be misleading, it’s important to realize that both features are meant from the pod’s perspective. Node affinity attracts pods to nodes, and pod affinity attracts pods to pods.
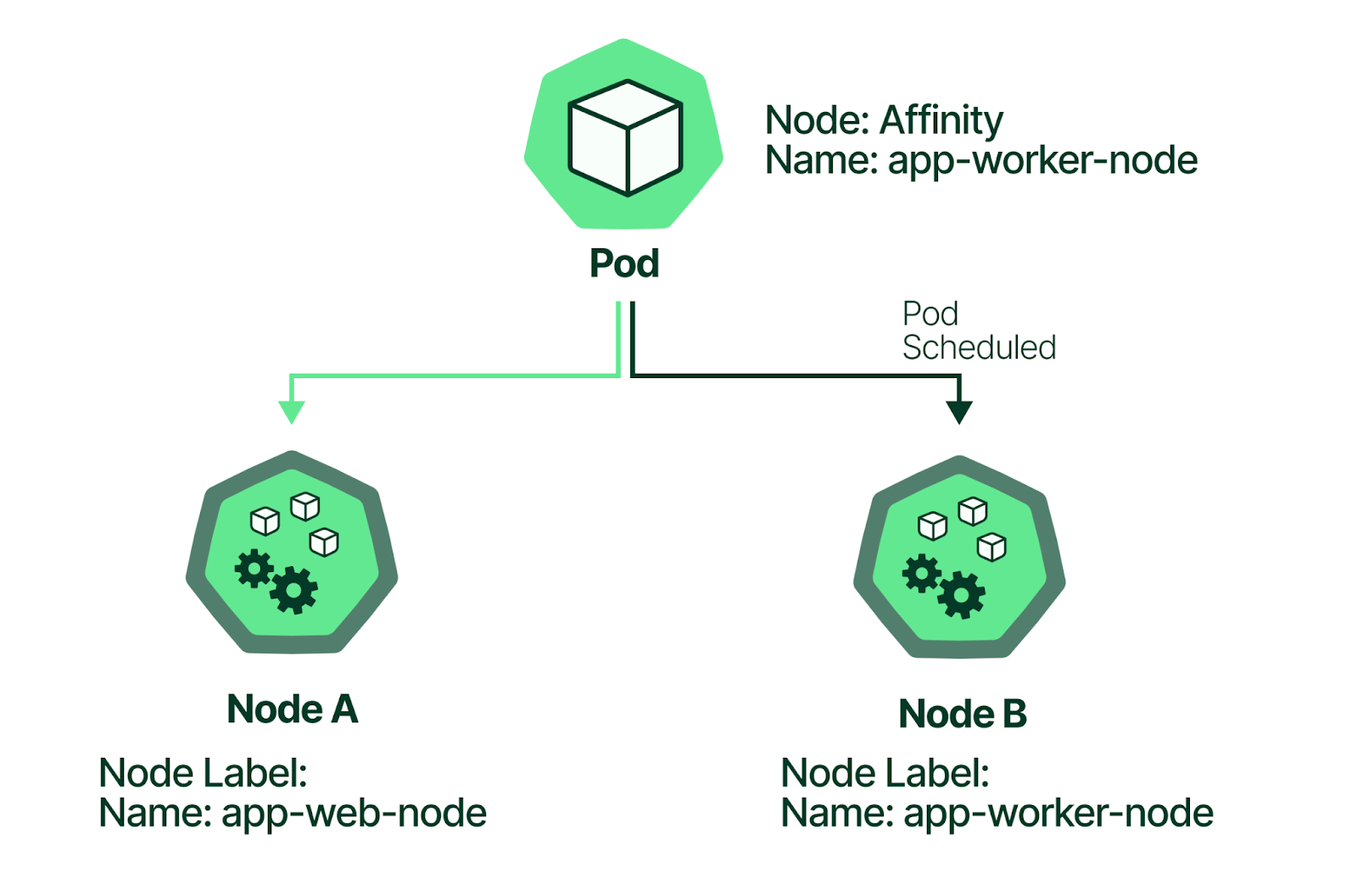
What is Kubernetes node affinity?
Kubernetes node affinity is a feature that enables administrators to match pods according to the labels on nodes.
It is similar to nodeSelector but provides more granular control over the selection process. Node affinity enables a conditional approach with logical operators in the matching process, while nodeSelector is limited to looking for exact label key-value pair matches. Node affinity is specified in the PodSpec using the nodeAffinity field in the affinity section.
What are pod affinity and anti-affinity?
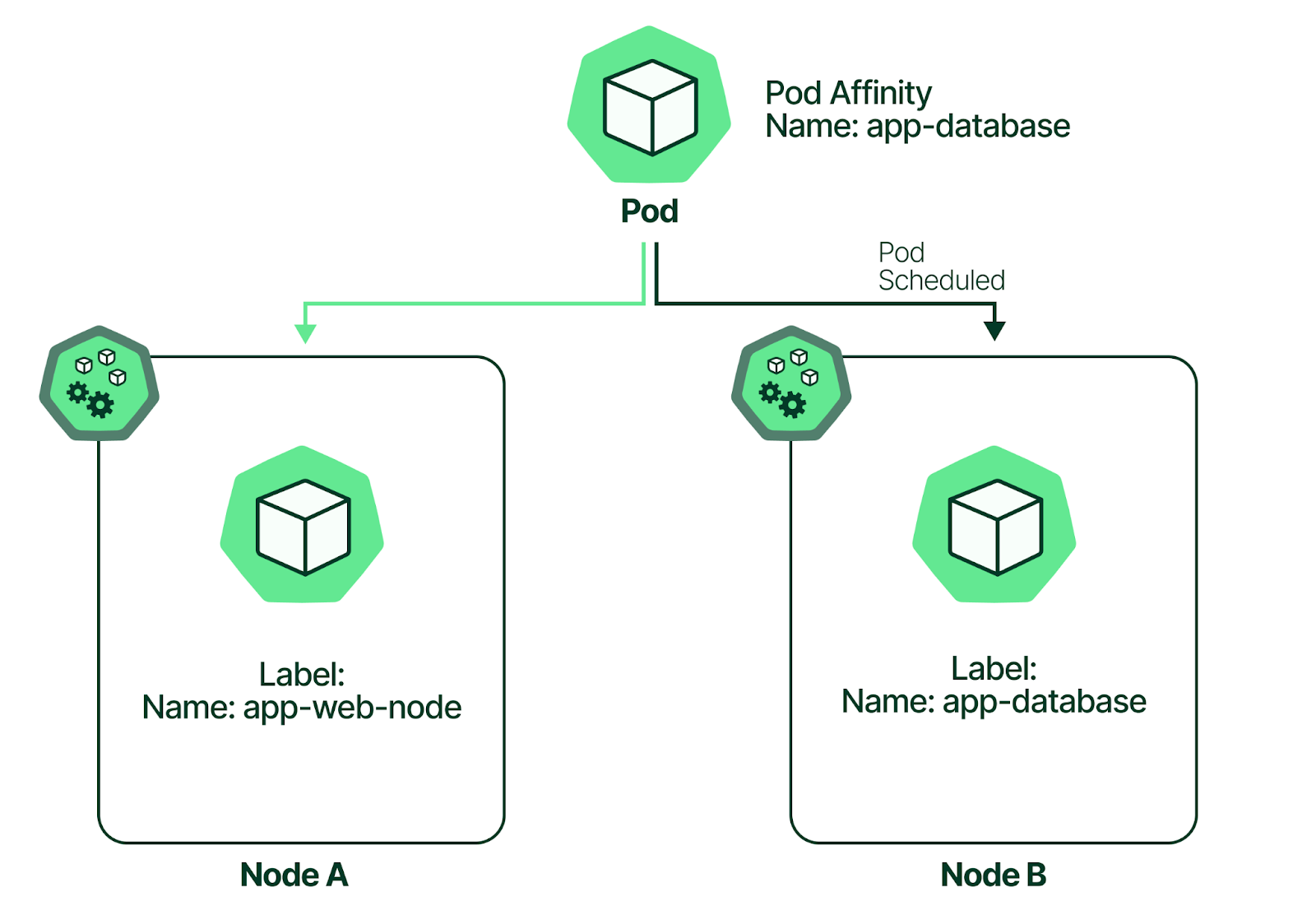
Pod affinity provides administrators with a way to configure the scheduling process using labels configured on the existing pods within a node.
A pod with a label key-value pair matching a condition can be scheduled on a node containing the matching labels.
As the name suggests, pod anti-affinity simply offers the opposite functionality. It prevents pods from being placed on the same node. For example, it can avoid placing two pods of the same application on the same Kubernetes node to offer redundancy in a failure scenario (more on this later).
Pod affinity and anti-affinity are also specified within the affinity section using the podAffinity and podAntiAffinity fields in the PodSpec.
Required vs. preferred rules
Both node affinity and pod affinity can set required and preferred rules that act as hard and soft rules. You can configure these rules with the following fields in a pod manifest:
- requiredDuringSchedulingIgnoredDuringExecution
- preferredDuringSchedulingIgnoredDuringExecution
These rules are valid for both node and pod affinity and can be configured using the respective affinity fields. Below are example rules to demonstrate this configuration method.
Kubernetes node affinity rule example
This rule shown below defines the following conditions:
- For a pod to be placed in a node, the node must have the value “app-worker-node” within the name label indicated by the required rule in the pod manifest.
- Nodes containing the key type with the value “app-01” are preferred.
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: name
operator: In
values:
- app-worker-node
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: type
operator: In
values:
- app-01
Kubernetes pod affinity rule example
This rule shown below defines the following conditions:
- A pod will only be scheduled on nodes where an existing pod has the key name with the value “web-app”.
- Pods that contain the key type and the value “primary” in the matching nodes are preferred.
- The topologyKey topology.kubernetes.io/zone ensures that the pod is scheduled only if the node is within the same zone as one of the existing pods with the matching key-value pairs. Note that some constraints are applied to the topology due to performance and security considerations found in the Kubernetes documentation.
- The weight field is used to define the priority of the conditions. Weight can be any value between 1 to 100. Kubernetes scheduler will prefer a node with the highest calculated weight value corresponding to the matching conditions.
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: name
operator: In
values:
- web-app
topologyKey: topology.kubernetes.io/zone
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 50
podAffinityTerm:
labelSelector:
matchExpressions:
- key: type
operator: In
values:
- primary
topologyKey: topology.kubernetes.io/zone
Anti-affinity vs. taints and tolerations
Our examples focused on the use case for node affinity which is designed to either attract or assign a pod to a node. The use case for anti-affinity may be less clear at this point. Conceptually, anti-affinity provides similar functionality as taints and tolerations in Kubernetes. Both features prevent pods from being scheduled on specific nodes. The primary difference is that anti-affinity uses matching conditions based on labels while taints are applied to the node and match tolerations defined in pod manifests.
If you want to stop pods from being scheduled on specific nodes, taints and tolerations are a better option. However, affinity, anti-affinity, taints, and tolerations are not mutually exclusive. You can combine them to facilitate complex scheduling scenarios. For example, suppose you want to reserve nodes in a Kubernetes cluster for an Elastic Search application but not host more than two instances of that particular application on the same node (to protect the application against a single node failure). In that scenario, you would take the following steps:
- Use taints on the reserved nodes and tolerations on the Elastic Search pods (this prevents any other application from placing pods on your reserved nodes).
- Use node affinity to assign or attract Elastic Search pods to those nodes (toleration along won’t assign those pods to the nodes so you must use affinity)
- Use pod anti-affinity to avoid having more than one Elastic Search pod on each node.
As you can see, the combination provides a new level of dynamic control over pod scheduling.
How to use affinity in Kubernetes
Let’s review how to utilize affinity in Kubernetes using an example. For this tutorial, we’ll use a Kubernetes cluster created with minikube v1.24.0 and Kubernetes 1.22.3 on Docker 20.10.8 on a Windows 10 environment. You can follow along in any compatible Kubernetes environment.
How to define Kubernetes node affinity
Node affinity depends on the labels specified on the node.
To begin, a label to the nodes using the kubectl label nodes command shown below:
kubectl label nodes minikube-m02 name=app-worker-node
node/minikube-m02 labeled
Here, we have labeled the minikube-m02 node containing the key name with the value app-worker-node.
You can see the labels configured on the specific node using the kubectl describe node command:
kubectl describe node minikube-m02
Name: minikube-m02
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=minikube-m02
kubernetes.io/os=linux
name=app-worker-node
Next, create a manifest that uses node affinity to match the pods with this specific node with the label. The manifest below defines a rule that enforces the given condition. The pod will only get scheduled on a node containing a label with the key name and the value app-worker-node.
apiVersion: v1
kind: Pod
metadata:
name: nginx-test
labels:
env: test-env
spec:
containers:
- name: nginx
image: nginx:latest
imagePullPolicy: IfNotPresent
resources:
requests:
memory: "128Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: name
operator: In
values:
- app-worker-node
We used the In operator in this manifest, but node affinity supports the following operators:
- In
- NotIn
- Exists
- DoesNotExist
- Gt
- Lt
Affinity can be configured using nodeSelectorTerms or matchExpression. The difference is that the pod can get scheduled to a node if any defined conditions match when multiple rules are configured using nodeSelectorTerms. On the other hand, the pod will get scheduled only if all the matchExpression rules are satisfied when using matchExpression.
Node affinity per scheduling profile
With the support of kube-schedule to configure multiple scheduling profiles, you can configure Kubernetes node affinity to provide different affinity rules for the specific scheduler profile. You can do this using the NodeAffinity plugin in the scheduler configuration.
There are two scheduler profiles in the configuration below: default-scheduler and web-scheduler. We have configured the NodeAffinity plugin to the web-scheduler. Therefore, the added affinity will only be applied to pods that set spec.schedulerName to web-scheduler. If the pod has its own node affinity configured in the PodSpec, both the rule configured in the PodSpec, and the scheduler-specific rules must match before a pod can be scheduled on a node.
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
- schedulerName: web-scheduler
pluginConfig:
- name: NodeAffinity
args:
addedAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: name
operator: In
values:
- web
How to define pod affinity/anti-affinity
Consider a use case where you want to schedule pods so all the pods on a node relate to the same application. You can do this with pod affinity. In fact, pod affinity is the preferred way to co-locate pods.
You can create an affinity rule that looks for key-value pairs from the pods currently residing in the node and schedules the pod to the node if a matching key-value pair is found. In the manifest below, pods are only scheduled to a node if there is a pod in the node with the key app-name and the value web-app.
apiVersion: v1
kind: Pod
metadata:
name: nginx-test
labels:
env: test-env
spec:
containers:
- name: nginx
image: nginx:latest
imagePullPolicy: IfNotPresent
resources:
requests:
memory: "128Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app-name
operator: In
values:
- web-app
topologyKey: topology.kubernetes.io/zone
While we used the In operator here, pod affinity supports the following operations:
- In
- NotIn
- Exists
- DoesNotExist
Now let’s look at a pod anti-affinity configuration. Suppose you want to schedule exactly one database pod per node. You can meet this requirement using anti-affinity, which will stop pods from getting scheduled if a pod within the node matches the specified rule. In the manifest below, a new pod will not be scheduled on the node if a pod has a key app-name and the value database.
apiVersion: v1
kind: Pod
metadata:
name: nginx-test
labels:
env: test-env
spec:
containers:
- name: nginx
image: nginx:latest
imagePullPolicy: IfNotPresent
resources:
requests:
memory: "128Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app-name
operator: In
values:
- database
topologyKey: topology.kubernetes.io/zone
Both pod affinity and anti-affinity rules can be configured in the same pod manifest to customize the scheduling process further. The manifest below consists of an affinity rule and an anti-affinity rule.
The pod affinity rule ensures that pods will only get scheduled to a node with at least a single pod with the matching key-value pair app-name: web-app. Meanwhile, the anti-affinity rule will try to keep pods from getting scheduled on nodes with containers with the key-value pair type: frontend.
apiVersion: v1
kind: Pod
metadata:
name: nginx-test
labels:
env: test-env
spec:
containers:
- name: nginx
image: nginx:latest
imagePullPolicy: IfNotPresent
resources:
requests:
memory: "128Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app-name
operator: In
values:
- web-app
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 10
podAffinityTerm:
labelSelector:
matchExpressions:
- key: type
operator: In
values:
- frontend
topologyKey: topology.kubernetes.io/zone
Conclusion
Affinity is one of the key features available in Kubernetes to customize and better control the pod scheduling process. Kubernetes pod and node affinity and anti-affinity rules enable cluster administrators to control where pods are allowed to be scheduled. Specifying multiple rules helps facilitate a wide range of scheduling configurations. Additionally, affinity can be combined with other features such as taints and tolerations to gain even greater control over the scheduling process. As a result, Kubernetes node affinity and anti-affinity and pod affinity and anti-affinity are important tools in a Kubernetes administrator’s toolbox.