Kubernetes cost monitoring: approaches & best practices
At Kubecost, we help teams monitor and manage Kubernetes spend. Teams commonly implement their first Kubernetes chargeback or showback solution with our software, and we frequently get asked questions about how to make this process go as smoothly as possible. This guide shares some of the different approaches to cost monitoring, best practices, and pitfalls that we’ve seen.
Our advice is distilled from our experience directly implementing chargeback at dozens of enterprises and from using chargeback systems at our previous companies. These experiences have taught us that situational variables matter, so think of these as general frameworks to apply to your organization’s specific situation. Reach out (team@kubecost.com) if you want to discuss!
Why bother with Kubernetes cost monitoring?
Kubernetes is an amazingly powerful platform that provides a set of APIs to dynamically provision compute/infrastructure resources. The Kubernetes platform is commonly used in dynamic, multi-tenant environments. The combination of these can enable teams to ramp resource consumption and costs quickly without clear visibility into why costs increased. Risks of overspending in this environment are furthered by the ability to easily provision expensive resources (e.g. GPUs) and by programmatic provisioning tools like cluster autoscaling. All of these mean that uncaught bugs or oversights can cause major cost overruns. Implementing a cost monitoring solution, along with a culture of awareness, can help catch these issues faster or even avoid them altogether.
Implementing cost monitoring can also help avoid the tragedy of the commons phenomenon, which is not uncommon in multi-tenant Kubernetes environments. The tragedy of the commons in this context is when all individual application engineering teams overprovision resources to ensure their applications are performant without appreciating the full cost of these resources. With every team overprovisioning pods/deployments/clusters independently, the company can be grossly inefficient with resources in aggregate. Small nudges towards awareness and accountability can help overcome many of these pitfalls and can also help avoid other security risks and developer productivity losses. The latter is true because teams often become more aware of abandoned or orphaned cloud resources, e.g. old deployments or persistent volumes.
Anecdotally, we have seen organizations consistently reduce spend by 30-70% after implementing cost monitoring solutions. We’ve just recently worked with a team that was unknowingly overspending by ~500%. Limited monitoring can have an immediate effect on reducing costs, but we have seen that implementing showback or chargeback can lead to greater savings and infrastructure hygiene.
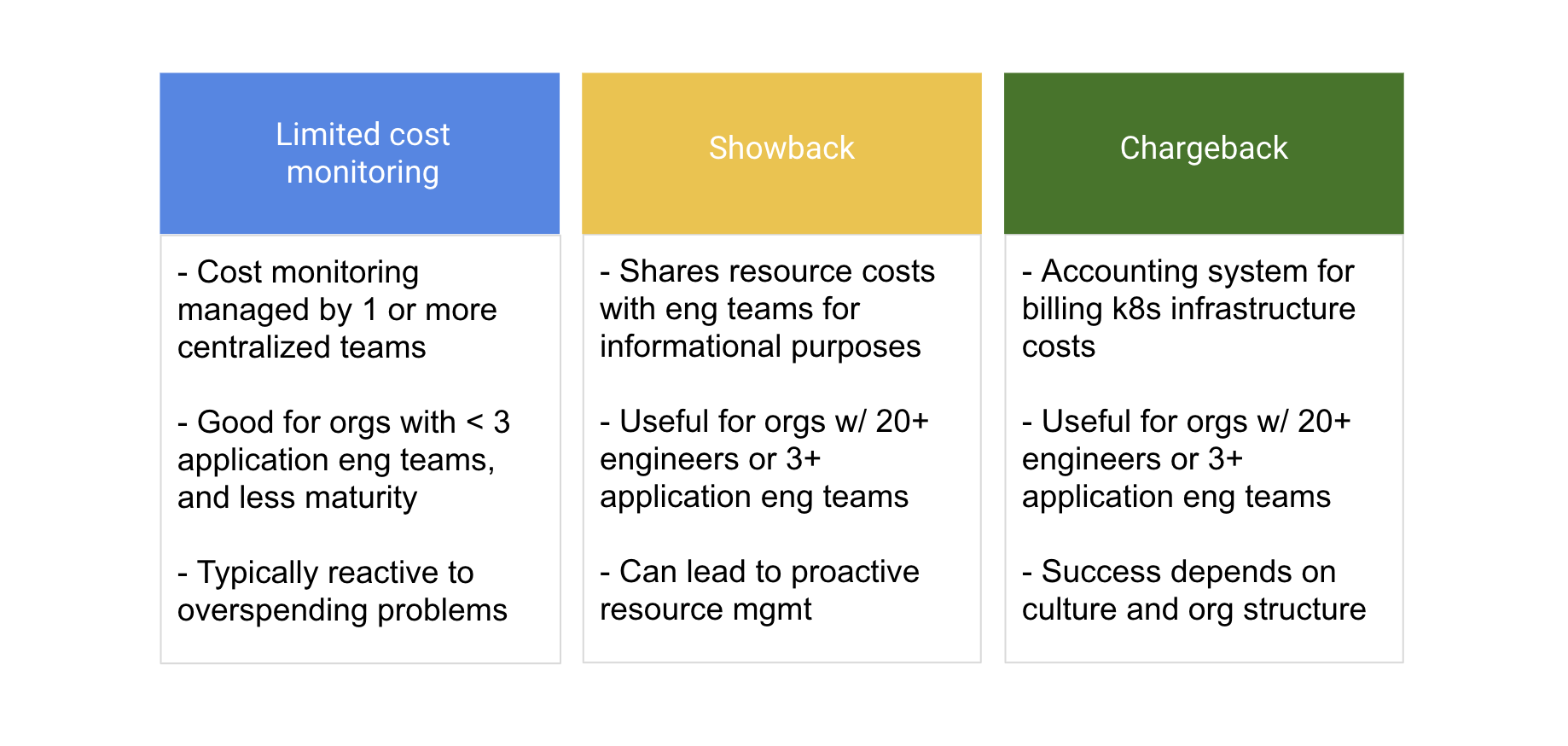
Cost monitoring approaches
Kubernetes chargeback is where an organization implements an accounting system to allocate k8s infrastructure costs and related cloud spend (e.g. databases and storage buckets) back to the individual teams or business units that consumed these resources. These internal or external clients actually receive bills for the resources they have consumed. Successful rollouts typically have broad organizational buy-in with expectations clearly communicated to engineering team leads.
Showback is a similar concept but does not actually cross-charge costs and instead broadly shares cost allocation data with teams for informational purposes only. While there are key differences between showback and chargeback, the majority of lessons we have learned apply to both.
There are also limited monitoring approaches where a subset of teams (e.g. DevOps and/or Finance) observe spend and then react appropriately. This can work in small organizations but is difficult in larger, multi-tenant Kubernetes environments.
We have also seen hybrid cost monitoring models where teams are only charged for resources if they go over a predetermined budget for their operations, or are only billed for certain resources. Hybrid approaches can be tricky and also require very clearly set expectations.
Best Practices & Recommendations
Here are some of the lessons we have learned when implementing cost monitoring systems with clients:
-
Don’t jump straight to chargeback. While chargeback may be right for your company, we recommend being incremental and starting with limited monitoring or showback. After teams have had a chance to review internal data for several months, moving to a chargeback model will go more smoothly. This is because teams oftentimes aren’t aware of the resources they are consuming and billing them without lead time can create a big surprise for a manager / team lead. We have found it’s best to share data first and make sure there is agreement on the right approach for allocation before actually billing teams.
-
Use transparency to establish a sense of fairness. Teams should be able to interpret and rationalize their bill. Cost allocation is complex in Kubernetes, so it’s important that allocation figures can be audited and reproduced. Open source and clear documentation can help immensely with this. Allocation models should also be built in a way that allows teams to take action to improve their resource efficiency over time. Here are some key questions to answer before gaining trust with teams and making data actionable:
- How are idle resources allocated? Answering this often depends on who makes cluster-level provisioning decisions.
- How are system or shared resources allocated? This depends on organizational structure and the amount of shared overhead.
- How do we clearly separate resources? We’ve seen that using namespaces for team/department allocation can lead to the cleanest division in resources. The right solution depends on organizational maturity though.
- Do we allocate based on resource requests or usage? Our experiences show that the max of requests and usage is often best, but this may not be correct for teams that don’t have control on setting both.
- How do you account for short-lived jobs? There are key technical decisions (e.g. sample frequency) that may impact how teams with short-lived but expensive jobs are billed.
-
Establish clear owners. We’ve seen that it’s important that each resource has a clearly established owner. This can be done effectively with an escalation approach or with admission controllers. An escalation approach can be implemented by defining an owner label at the deployment level, namespace level, and at the cluster level. This creates a clear escalation path should a major issue arise. This labeling can be enforced with an Open Policy Agent or directly an admission controller webhook.
-
Review data on a consistent basis. We’ve seen teams that proactively review data, typically on a weekly or bi-weekly basis, are able to quickly catch or prevent any major wasteful cloud spending. Regularly emails, in addition to alerts for egregius overspending, can help ensure issues get caught quickly without being a major distraction.
Most Kubernetes chargeback efforts hit roadblocks not because of technical challenges but because of practical implementation setbacks. Establishing transparency and a sense of fairness across business units and application engineering teams requires both the right tools, transparency, and documentation. Effective cost and resource monitoring in a Kubernetes environment can lead to big gains, consistently reducing cloud spend by 30% or more. It can also help create a culture of awareness with other impact on security and productivity.
Kubecost uses open source models to monitor and manage resources in dynamic Kubernetes environments. Reach out (team@kubecost.com or Slack) or visit our website if you want to learn more.