A guide to spot-readiness in Kubernetes
Using spot nodes in your Kubernetes cluster can be intimidating due to their lack of availability guarantees. Kubecost’s Spot-Readiness Checklist is here to give you more confidence: the checklist investigates your public cloud Kubernetes workloads to identify candidates for safe scheduling on spot instance types, which can save you up to 90% on cloud resource costs. Kubecost automatically performs a series of checks on your AWS (EKS), Azure (AKS), and Google Cloud (GKE) clusters using your workload configurations to determine readiness. It then estimates the savings impact from making the transition to Spot.
What are spot instances and why use them?
Spot instances are spare compute instances that public cloud providers offer to customers at a deeply discounted rate—potentially up to 90% cheaper. However, spot nodes vary in their availability and pricing, depending on the supply and demand of compute resources at a given time, and fluctuate per instance size, instance family, and deployment location. Once demand for a particular instance type increases, spot instances may receive an interruption notice and spin down within a short shutdown window (usually a few minutes). For this reason, spot resources are best used for fault-tolerant and flexible applications like Spark/Hadoop nodes, microservices that can be replicated, etc.
Kubernetes enables dynamic replication and scalability of workloads in a way that allows many applications to be resilient to node failure, so it is in many ways the perfect tool to embrace spot instances. For example, when using AWS EKS, schedulers will detect pods or containers running on spot instances and replace them with on-demand resources when spot instances become unavailable.
What’s the customer challenge today?
Customers frequently tell us they are unaware that spot instances are supported by Public Cloud Kubernetes services. Spot instance support for GKE launched in 2018, but support is very new for both AKS (Oct. 2020) and EKS (Dec. 2020). Once aware of this support, many customers struggle to identify which workloads are suitable to run on spot instances. Identifying spot-applicable workloads on your own can be difficult or even intimidating, given Cloud Providers explicitly warn they have “no availability guarantees” and are only for fault-tolerant applications. If spot compute resources are not implemented correctly they can result in costly downtime.
Enter… Kubecost’s Spot-Readiness Checklist
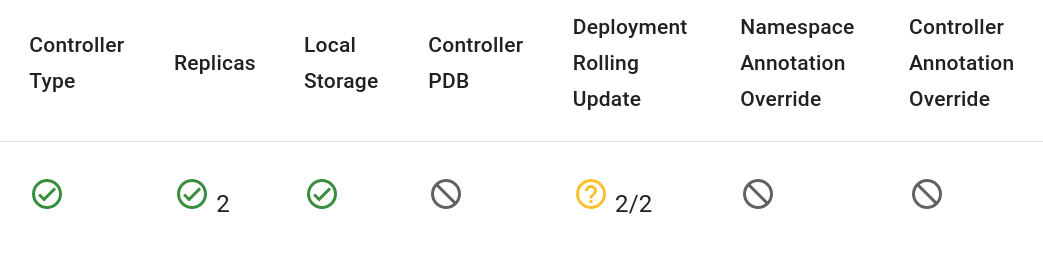
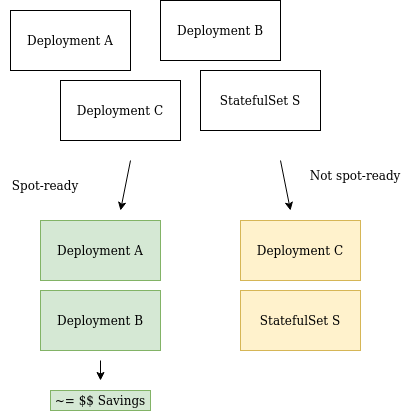
Kubecost’s Spot-Readiness Checklist provides six checks on your Kubernetes workloads to determine their spot readiness: Controller Type, Replica Count, Local Storage, Controller Pod Disruption Budget, Rolling Update Strategy, and Manual Annotation Overrides. Below is an overview of each of these features. The Checklist will mark controllers in the cluster as spot-ready, maybe spot-ready, or not spot-ready based on the combined results of all checks.
-
Controller Type - Kubecost is configured to investigate a fixed set of controllers—currently Deployments and StatefulSets (we are continually adding functionality here!).
Deployments are considered spot-ready because they are relatively stateless, intended to only ensure a certain number of pods are running at a given time. StatefulSets, however, should generally be considered not spot ready. Scheduling StatefulSet pods on spot nodes can lead to data loss. However, if a StatefulSet workload meets all other checks, it may be worth evaluating if deploying the workload as a StatefulSet is necessary.
-
Replica Count - Workloads with a configured replica count of 1 are not considered spot-ready because if the single replica is removed from the cluster due to a spot node outage, the workload goes down until it is rescheduled. Replica counts greater than 1 can signify a level of spot-readiness because workloads that can be replicated tend to also support a variable number of replicas.
-
Local Storage - Currently, workloads are only checked for the presence of an emptyDir volume. If one is present, the workload is assumed to be not spot-ready.
More generally, the presence of a writeable volume implies a lack of spot readiness. If a pod is shut down non-gracefully while it is in the middle of a write, data integrity could be compromised. More robust volume checks are currently under consideration.
-
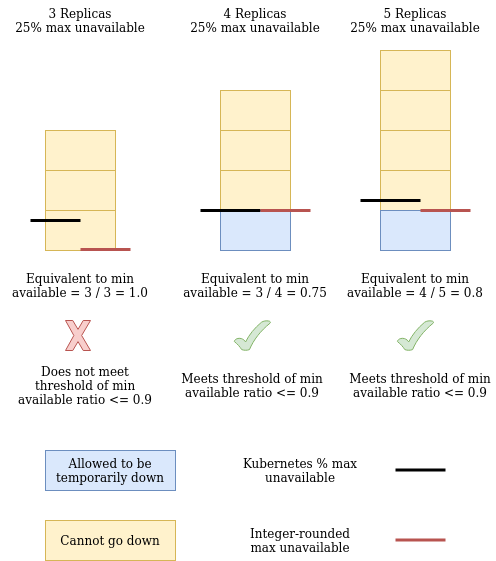
Pod Disruption Budget - It is possible to configure a Pod Disruption Budget (PDB) for controllers that causes the scheduler to (where possible) adhere to certain availability requirements for the controller. If a controller has a PDB set up, we read it and compute its minimum available replicas and use a simple threshold on the ratio (min available / replicas) to determine if the PDB indicates readiness. See a visualization of this ratio calculation in the Rolling Update Strategy section. We chose to interpret a ratio of > 0.5 to indicate a lack of readiness because it implies a reasonably high availability requirement.
If you are considering this check while evaluating your workloads for spot-readiness, do not immediately discount a workload because of this check failing. Workloads should always be evaluated on a case-by-case basis and it is possible that an unnecessarily strict PDB was configured.
-
(Deployment only) Rolling Update Strategy - Deployments have multiple options for update strategies and by default they are configured with a Rolling Update Strategy (RUS) with 25% max unavailable. If a deployment has an RUS configured, we do a similar min available calculation (from max unavailable in rounded-down integer form and replica count) as with PDBs, but threshold it at 0.9 instead of 0.5. Doing so ensures that default-configured deployments with replica counts greater than 3 will pass the check.
-
Manual annotation override - We also support manually overriding the spot readiness of a controller by annotating the controller itself or the namespace it is running in with
spot.kubecost.com/spot-ready=true.
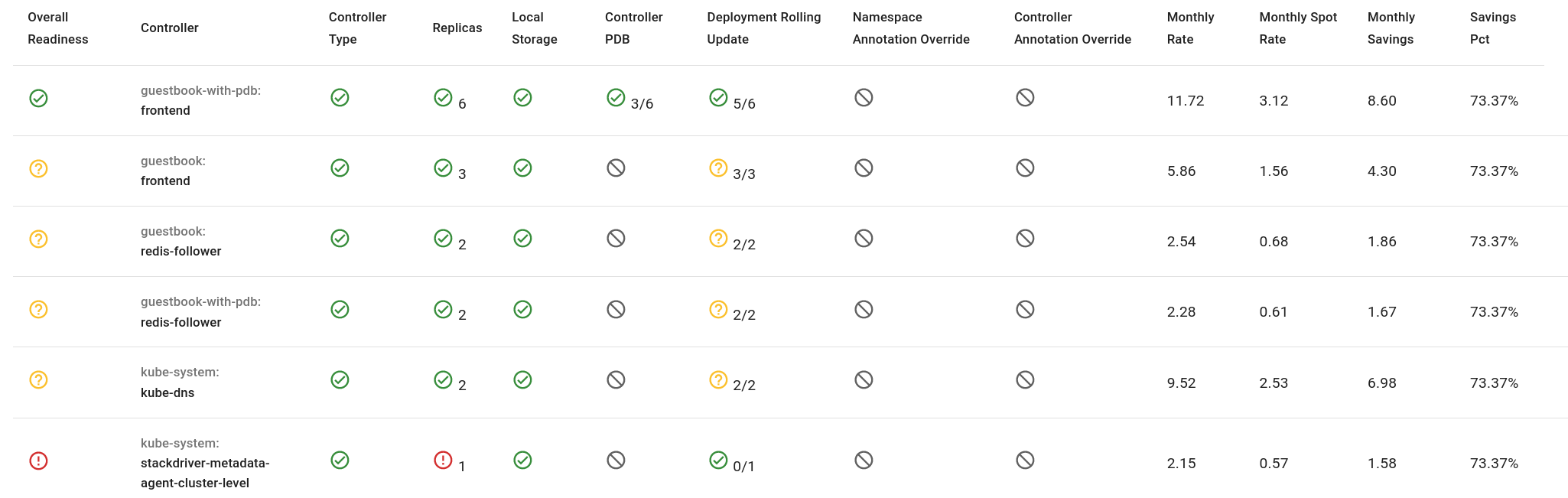
For AWS and GCP clusters, the checklist will also estimate the savings of moving the workload to run on spot nodes based on approximate spot node pricing for your cloud provider. Here’s what it looks like!
Implement spot nodes in your cluster using Kubecost, for free!
Kubecost is a free and open-source tool that can help implement spot node savings on your Kubernetes workloads. Usage data collected by Kubecost never leaves your cluster, enabling customers to adopt our tool quickly without the security and data governance risks associated with sharing this data remotely.
Kubecost marking a workload as spot-ready is not a guarantee. A domain expert should always carefully consider the workload before approving it to run on spot nodes. We recommend using taints and tolerations to schedule only spot-ready workloads on spot nodes. We are currently developing a feature to translate these recommendations and estimates into more concrete actions you can take: resizing your cluster node groups/pools with spot and moving compatible workloads to the new nodes. Be on the lookout for this powerful new functionality!
To get started, just install Kubecost with Helm (takes ~2 minutes):
helm repo add kubecost https://kubecost.github.io/cost-analyzer/
helm upgrade -i --create-namespace kubecost kubecost/cost-analyzer --namespace kubecost --set kubecostToken="spot-ready"
Kubecost is available for download as a Helm chart at this link that contains further instructions: https://www.kubecost.com/install.html.