Intelligently adapt Kubernetes clusters to use spot nodes
Running Kubernetes in the cloud isn’t cheap, and cloud providers understand that their customers want options to reduce the cost of Kubernetes. AWS, GCP, and Azure currently support using “spot” (or “preemptible”) nodes in Kubernetes clusters. Spot nodes generally come from excess compute capacity in a datacenter and are offered by cloud providers at a steep discount (up to 90%!)—with the caveat that the provider can take that node away on very short notice. The Kubernetes scheduler is adept at moving workloads when available compute resources change (and is getting even better on GCP and AWS, thanks to the graceful node shutdown feature), making Kubernetes well-suited to using spot nodes for compute. However, identifying workloads that are safe to run on spot—and then selecting the correct node types and quantities to handle the split of spot-ready and non spot-ready workloads—is no easy task. That’s where Kubecost’s Spot Commander can help!
Analyze your cluster’s workloads for spot-readiness
First, Kubecost analyzes the workloads running on your cluster to determine their spot-readiness using the Spot Checklist feature. We’ve written in detail in a previous post about how the Spot Checklist works. At a high level, it uses information from the Kubernetes API and heuristics to identify workloads that are spot ready.
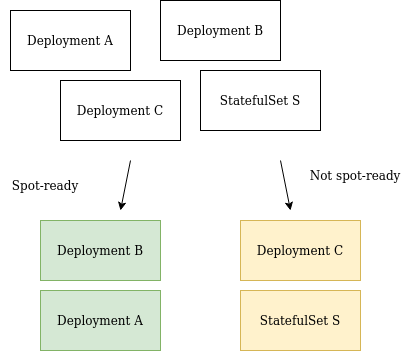
Suggest cluster configuration to support spot-ready and non-spot-ready workloads
Once Kubecost has identified which workloads on your cluster can run on spot, it’s time to optimize your cluster configuration. Kubecost can leverage its extensive knowledge of (1) your workloads’ usage patterns and (2) your cloud provider’s node capacities and pricing to suggest the least expensive node types and quantities to support both your spot-ready and non spot-ready workloads. If you have specific constraints you want to impose on this process, like minimum node counts for node pools, a certain resource overhead to have available on all nodes, or a restriction on using shared-core machine types, you can configure these in the UI!! Your overall savings for adopting the new cluster configuration is calculated by comparing the current run-rate of your cluster’s nodes and with the approximate run-rate of the new configuration. For a more in-depth look at how we determine cluster configuration, see our official documentation.
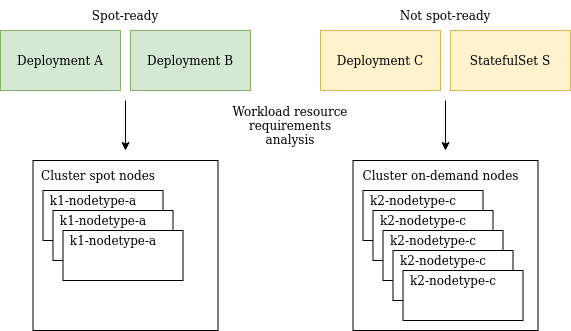
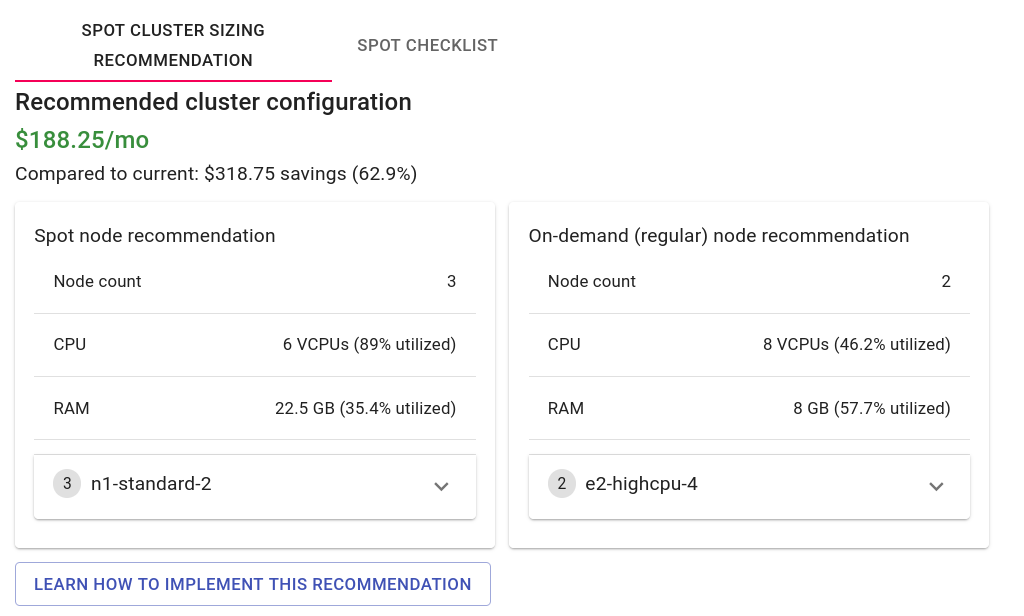
Adopting the recommended configuration
To realize those estimated savings, you’ll need to update your cluster configuration to include the new spot nodes, reduce the number of on-demand nodes, and also make sure that only spot-ready workloads are scheduled on spot nodes. We’ll walk through the process together in the steps below.
First, we have to let Kubernetes know which workloads are spot-ready. To do so, we’re going to use taints and tolerations to make the spot-ready workloads “tolerate” running on a spot node. We might add the following toleration to Deployment A:
tolerations:
- key: "spotnode"
operator: "exists"
effect: "NoSchedule"
Next, create a new set of spot nodes in your cluster (a “node pool” in GKE or “nodegroup” on EKS). Follow your provider’s documentation! When creating the nodes, make sure to add the equivalent taint so that only workloads with the appropriate spot toleration get scheduled on those nodes. If the tools you are using don’t support tainting at node creation time, you can always use good ol’ kubectl:
kubectl taint nodes SpotNode1 spotnode=true:NoSchedule
Finally, alter the set of on-demand nodes in your cluster to be in line with Kubecost’s recommendation. You can do this by resizing your current set of on-demand nodes or by creating a new set and deleting the old one. Once you’ve removed some of the current on-demand capacity in the cluster, you should notice the workloads with the new spot toleration getting scheduled onto the new spot nodes!
If you’re using GKE, Spot Commander can generate a set of gcloud and kubectl commands that you can run in your terminal to adopt the recommended cluster configuration. These commands add tolerations to spot-ready workloads, create the new spot and on-demand node pools, and then delete old node pools.
Start implementing spot nodes using Spot Commander for free
Spot Commander is available as part of the free community version of Kubecost, a tool that can help you monitor cluster costs and implement spot node savings for your Kubernetes workloads. Usage data collected by Kubecost never leaves your cluster, allowing for quick adoption without the need for lengthy internal security and data governance reviews.
To get started, just install Kubecost with Helm (takes ~2 minutes):
helm repo add kubecost https://kubecost.github.io/cost-analyzer/
helm upgrade -i --create-namespace kubecost kubecost/cost-analyzer --namespace kubecost --set kubecostToken="QnJkV0psWTI5emRDNWpiMjA9eG0zNDN"
Other installation instructions can be found at https://www.kubecost.com/install.html.
A final note: Kubecost marking a workload as spot-ready is not a guarantee. A domain expert should always carefully consider the workload before approving it to run on spot nodes. Particularly complex clusters may need a more involved node configuration than Kubecost currently provides, but we hope our recommendations and the promise of our estimated savings will motivate your infrastructure teams to start adopting spot and realizing those awesome cost reductions. If you run a massive cluster, Kubecost’s estimated savings may not be accurate, because moving a substantial number of nodes to spot can have a major impact on spot node availability. Do your research if you think you’re in this category! Your provider probably has a rep you can ask.