Kubecost Brings NVIDIA GPU cost monitoring for AI workloads in 2.4

We wrote previously about some of the nice features Kubecost 2.4 brings including the beta launch of Oracle Cloud Infrastructure (OCI) cost monitoring. Highlighting another gem in this release, Kubecost has added NVIDIA GPU cost monitoring in the 2.4 release which is now AI workload ready. This release brings GPU utilization and efficiency into Kubecost allowing you to truly see where your spend for GPUs is going and help you identify how to be more efficient.
Kubecost 2.4 brings GPU utilization into the equation in order to build a picture of GPU efficiency. By understanding how much of a GPU a container uses, Kubecost therefore understands how much is idle. And with an understanding of both, it becomes possible to determine how efficiently a workload is using that GPU.
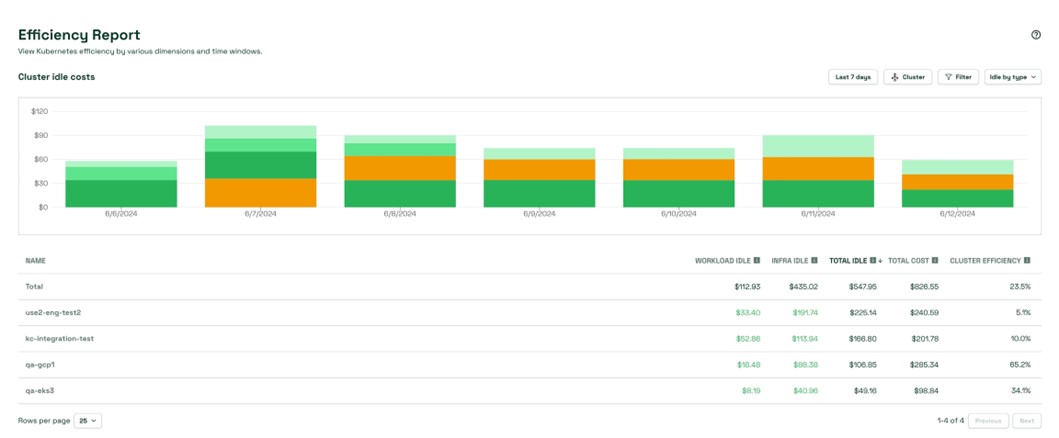
Although several areas of Kubecost have been enhanced with this new sense of GPU awareness, the Efficiency Report, introduced in Kubecost 2.3, is the real star of the show. The Efficiency Report now includes columns for GPU Workload Idle as shown below. When accessing the “Resource idle by workload” view of the Efficiency Report, this column will provide a cost associated with the portion of a GPU requested by your containers but unused. Especially for those AI/ML workloads which often saturate a GPU but only for a short period of time and then keep running, this view helps you understand how to locate those workloads.
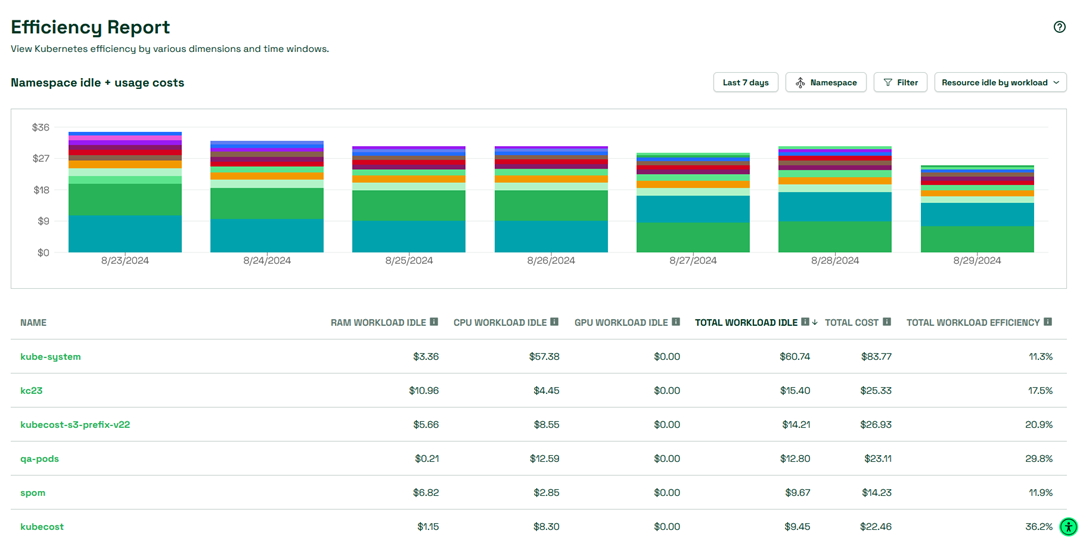
Kubecost doesn’t stop there but also includes a window into your infrastructure idle. In the “Resource idle by cluster” view shown below, the Efficiency Report will also show you GPUs which have not been requested at all and the wasted cost associated. This view is critical for helping you identify large areas of waste associated with GPUs populated in nodes which are completely unused.
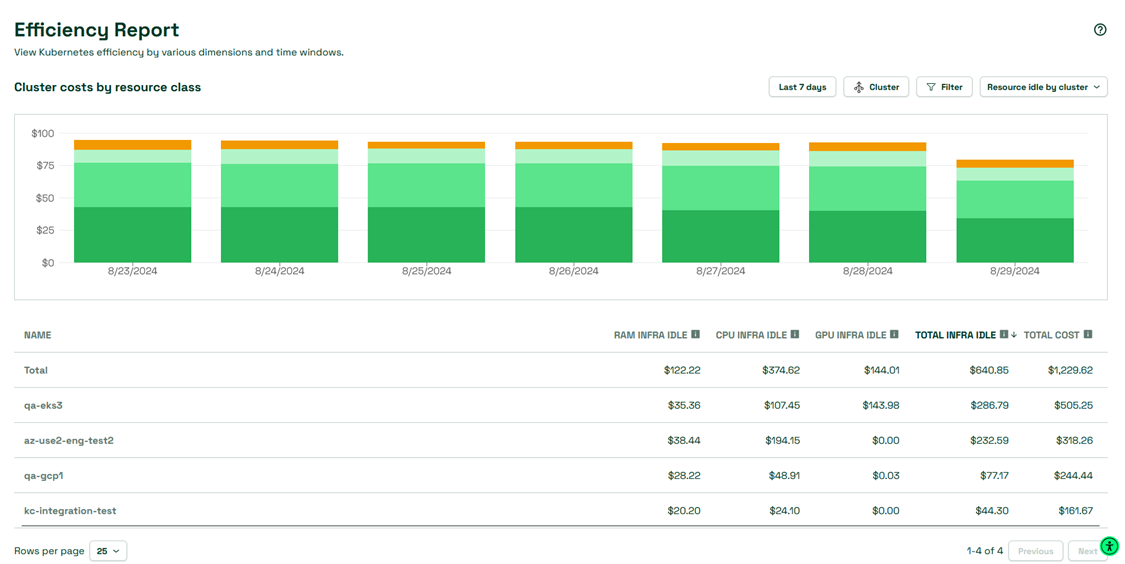
You can also expect to see other areas of Kubecost 2.4 include similar notions of GPU efficiency in widgets for many different resources in the UI, for example on the Overview and Cluster Details pages.
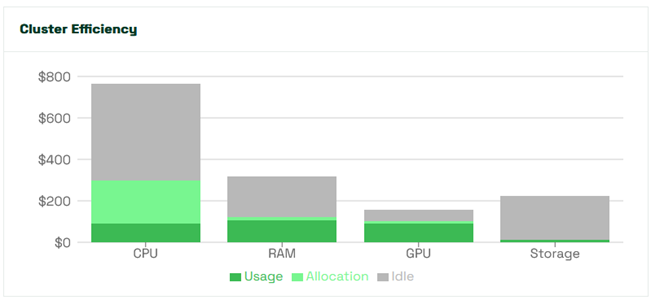
In order to make all this happen, Kubecost 2.4 will require the industry-standard NVIDIA component DCGM Exporter which monitors GPUs on Kubernetes nodes and exports metrics in Prometheus format. For more information on how to get up and running, please see our documentation here.
To get started quickly with DCGM Exporter, once you’ve identified the label you use for GPU nodes, add this to a values-dcgm.yaml values file.
serviceMonitor:
enabled: false
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: mylabel
operator: In
values:
- "myvalue"
Then go ahead and install the chart.
helm upgrade -i dcgm dcgm-exporter \
--repo https://nvidia.github.io/dcgm-exporter/helm-charts \
-n dcgm-exporter --create-namespace \
-f values-dcgm.yaml
FAQ
Q: How does this release differ from previous releases when it comes to GPU costs?
A: In Kubecost 2.4, the allocated cost of a GPU will be determined by that container’s usage of the GPU and not by its presence. For example, if a $100/mo. GPU was only being half used, the allocated cost to the container would be around $50 and not the full $100.
Q. Does this require an upgrade of my agents?
A. Yes, this requires you upgrade your agents to 2.4.
Q. What’s next for Kubecost?!
A. In 2.5 and forward, expect to see more exciting enhancements around GPUs including taking efficiency to the next level with proactive savings recommendations.
Q. In what Kubecost editions is this available?
A. All editions of Kubecost, including free, contain this feature.
Q. Is any of this available for OpenCost?
A. Yes! Support for GPU utilization was also added in OpenCost between 1.111 and 1.112, so if you’re a user of OpenCost you should also be able to see your GPU allocation data reflect actual usage.
Closing
Kubecost 2.4 has many valuable enhancements including expanded NVIDIA GPU support which brings GPU monitoring into the picture. This capability helps to ensure that your GPU workloads including AI and ML remain cost compliant through a holistic picture of efficiency, and best of all, it’s available in all editions of Kubecost (including free!).
In the future, be on the lookout for more enhancements in this area including proactive GPU savings!