Achieving Cost-Effective Scaling in Kubernetes

Introduction
Scaling applications in Kubernetes can be both a necessity and a challenge. While Kubernetes offers powerful tools for scaling up and out, doing so without a strategic approach can lead to unnecessary costs and suboptimal performance. In this post, we’ll explore best practices for achieving cost-effective scaling of your Kubernetes applications, ensuring you get the most out of your resources while maintaining a satisfying user experience.
Understanding Cost-Effective Scaling
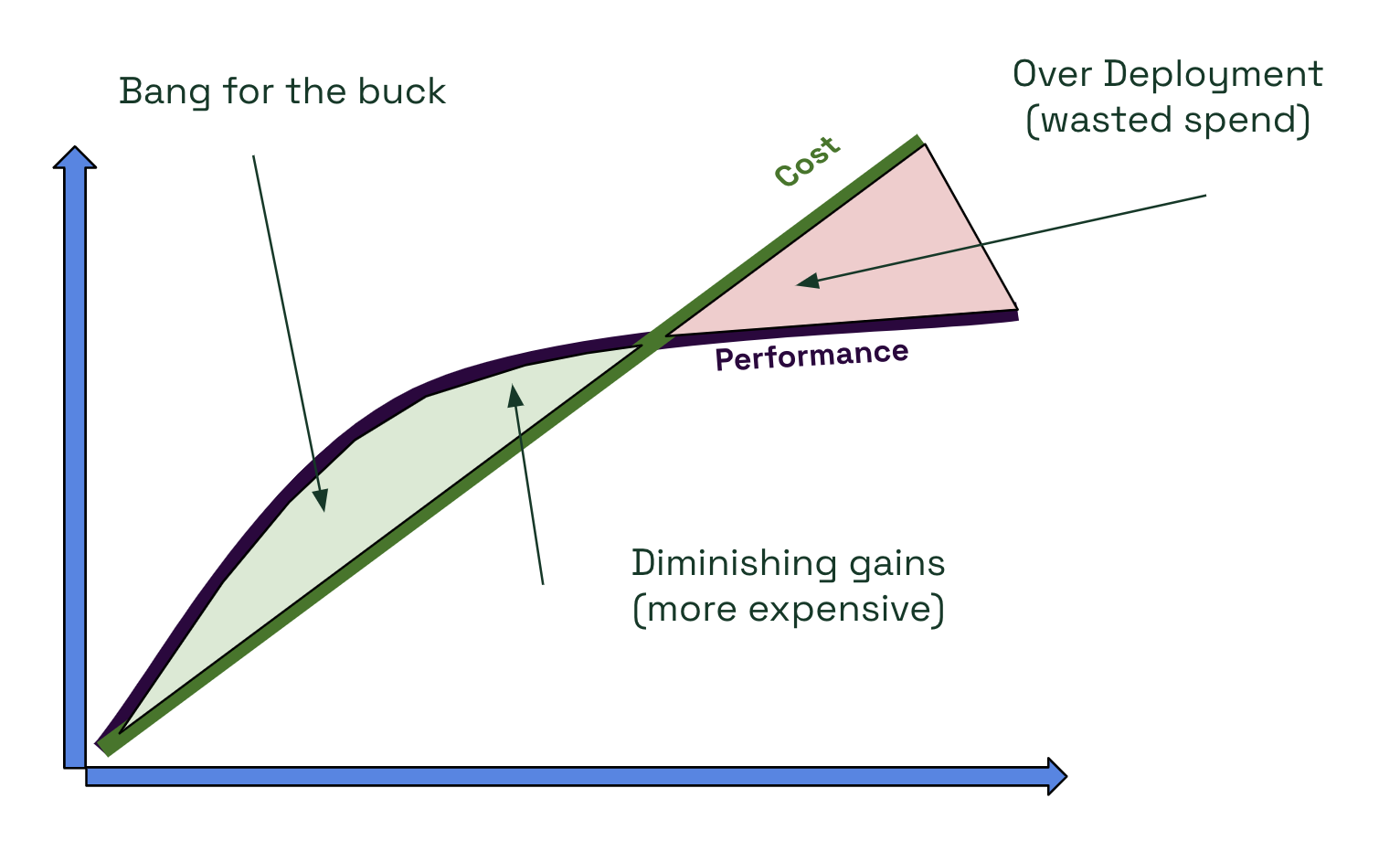
Before diving into strategies, defining what we mean by cost-effective scaling is essential. Simply put, cost-effective scaling is spending the least amount of money possible to achieve the desired performance levels needed to ensure a satisfying user experience for the customer.
It’s crucial to recognize that throwing more resources at an application doesn’t always translate to proportional performance gains. Most applications have a sweet spot where they deliver optimal performance for the resources allocated. Beyond this point, additional spending can result in diminishing returns or even wasted resources.
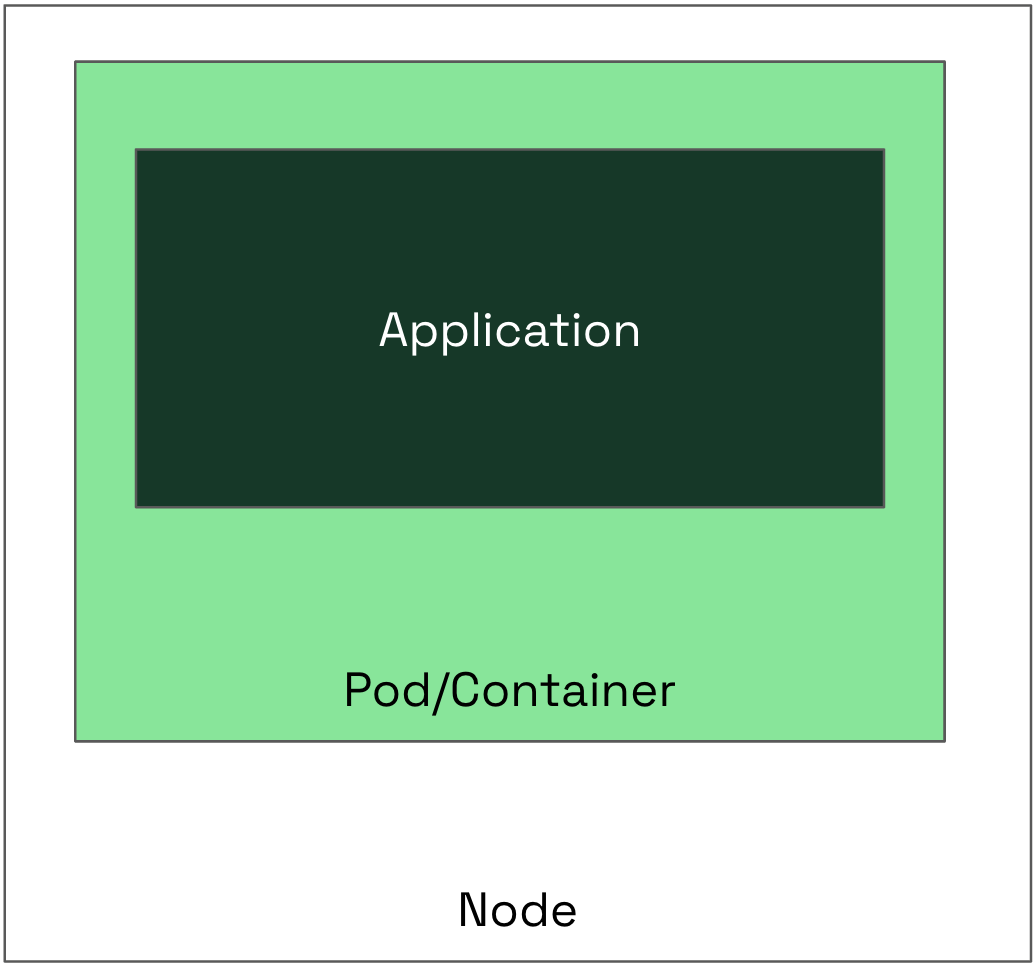
The Layered Approach to Scaling Kubernetes Applications
Much like onions (or ogres, if you’re a fan of “Shrek”), Kubernetes applications have layers. Understanding and optimizing each layer is key to achieving cost-effective scaling. The primary layers to consider are:
- Application Layer
- Container Layer
- Node Layer
Changes made at the inner layers can have significant impacts on the outer layers. For example, tuning your application can influence how you right-size your containers, which in turn affects node utilization.
Tuning the Application Layer
The innermost layer is the application itself. Tuning at this level can dramatically affect both performance and cost. It’s best to tune applications in the design phase, but you can still tune hardware, resource allocations and prioritizations to make applications perform better and with less waste.
Code-Level Optimizations
Working with your development team to optimize the application’s code can lead to more efficient resource usage.
This includes:
- Eliminating memory leaks
- Optimizing algorithms
- Reducing CPU-intensive operations
Runtime Configurations
Adjusting runtime settings can also improve performance without changing the codebase.
Consider:
- Tuning garbage collection settings
- Adjusting thread pools
- Configuring caching mechanisms
By effectively tuning the application, you can adjust the performance curve, achieving greater performance with the same or even fewer resources.
Right-Sizing Containers
After tuning the application, the next step is to right-size your containers. This involves matching the resources you’ve allocated (CPU, memory) with the actual utilization, while leaving some headroom for utilization spikes to ensure availability.
Measuring Efficiency
Efficiency can be measured as: Efficiency (%) = (Actual Resource Utilization / Allocated Resources) * 100
Aim for the highest efficiency possible without compromising application performance.
This may involve:
- Collecting utilization data over time, including peak periods
- Adjusting resource requests and limits accordingly
- Allowing for a safety margin to handle unexpected spikes
Right-Sizing Nodes
Optimizing node utilization is crucial for cost savings, as nodes are a significant cost factor in Kubernetes clusters.
Reducing Idle Resources
Identify and minimize idle resources (often referred to as “white space”) on nodes by:
- Adjusting node sizes to better fit your workload
- Selecting appropriate node types (e.g., compute-optimized, memory-optimized)
- Consolidating workloads to maximize node utilization
Considering Availability Requirements
Ensure that right-sizing efforts do not compromise application availability.
Account for:
- Redundancy needs
- Uptime requirements
- Mean time to recovery (MTTR)
Sometimes, intentionally leaving some capacity unused is necessary to meet high availability standards.
Collecting and Analyzing Data
Data is the backbone of cost-effective scaling. Without timely and accurate data, performance at scale will be experimental and unpredictable at best.
Two critical types of data are:
- Cost Allocation Data: Understanding where your costs are incurred at a granular level (per application, team, or business unit).
- Resource Utilization Data: Monitoring actual resource usage over time.
Importance of Granularity
Having detailed, granular data allows for more precise optimizations.
Granularity enables:
- Accurate budgeting and forecasting
- Fair cost distribution among teams (chargeback/showback)
- Identification of inefficiencies and areas for improvement
Balancing Cost and Performance
With comprehensive data, you can map out your cost vs. performance curve and identify optimization opportunities to optimize.
Finding the Sweet Spot
- Avoid Over-Provisioning: Ensure that you’re not allocating more resources than necessary.
- Optimize for Both: In many cases, it’s possible to reduce costs while maintaining or even improving performance.
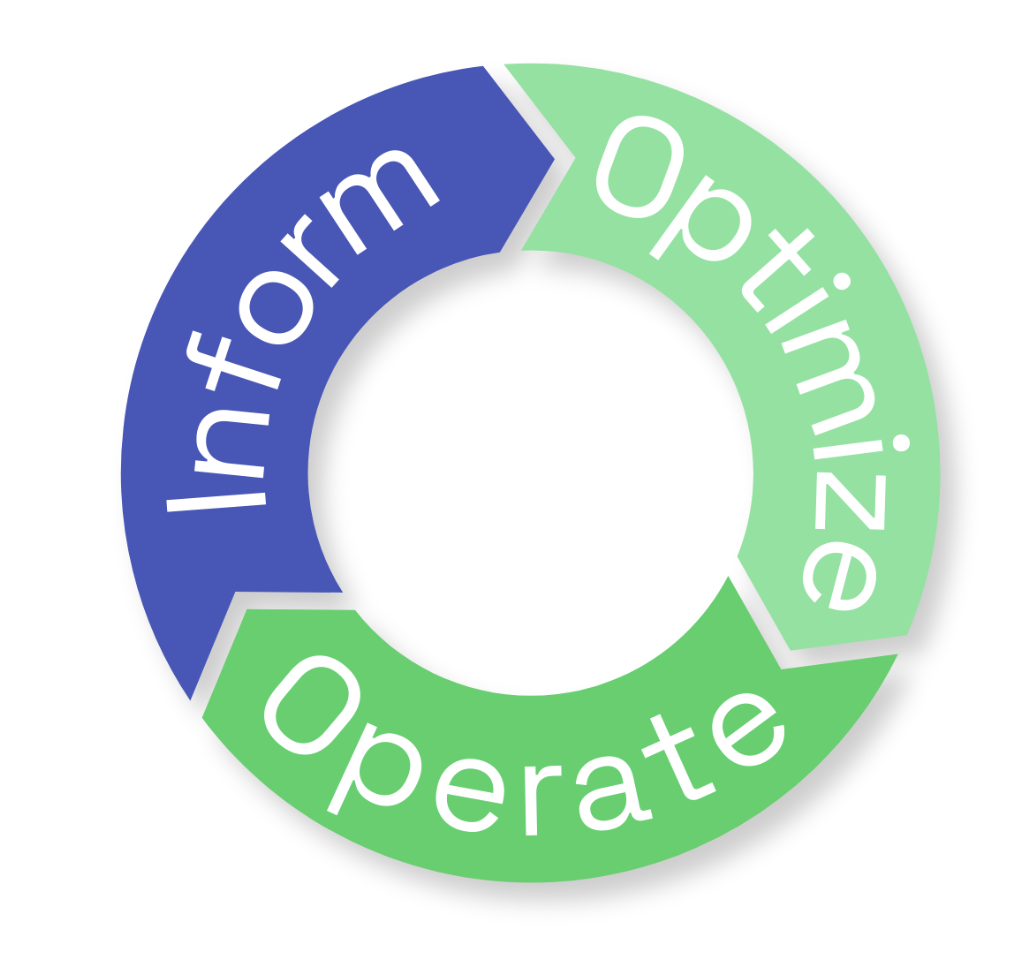
Aligning with FinOps Principles
FinOps is a framework that promotes efficient cloud spending through collaboration and data-driven decision-making.
The three key phases are:
- Inform: Collect and share cost and usage data.
- Optimize: Identify and implement cost-saving opportunities.
- Operate: Continuously monitor and refine operations for ongoing efficiency.
By following FinOps principles, organizations can foster a culture of accountability and continuous improvement.
The Role of Auto Scalers
Auto scalers in Kubernetes (such as the Horizontal Pod Autoscaler or Cluster Autoscaler) are powerful tools, but they should be used wisely and with care.
Limitations of Auto Scaling
- Scaling Inefficiencies: If your resources are not optimized, auto scalers will scale those inefficiencies, leading to higher costs.
- Not a Substitute for Optimization: Auto scalers react to metrics but do not optimize resource requests or fix application inefficiencies.
Best Practices
- Optimize First: Ensure that your application and resources are right-sized before relying heavily on auto scalers.
- Monitor Scaling Behavior: Regularly review how auto scaling affects your costs and performance.
Conclusion
Achieving cost-effective scaling in Kubernetes requires a strategic, data-driven approach that addresses each layer of your applications and infrastructure. By tuning your applications, right-sizing containers and nodes, and aligning with FinOps principles, you can optimize both performance and cost.
Remember, this is an iterative process. Regularly collect data, review your resource utilization, and adjust as needed to maintain optimal efficiency.
Interested in optimizing your Kubernetes costs? Get started with Kubecost today.