Kubernetes Cluster Size: Your Guide to Optimization

Introduction
One of the most impactful ways to reduce spend on Kubernetes infrastructure is to make sure your clusters are optimally sized for the workloads they run. It’s not always so obvious how to arrive at an optimally-sized cluster, even in autoscaling environments. Kubecost’s cluster right-sizing recommendations help users bridge this gap to newfound cost optimization. Users implementing this tool have realized savings in the range of 25-60%, even having a major impact in autoscaling environments. In this guide, we will cover the importance of right-sizing clusters and how Kubecost can help.
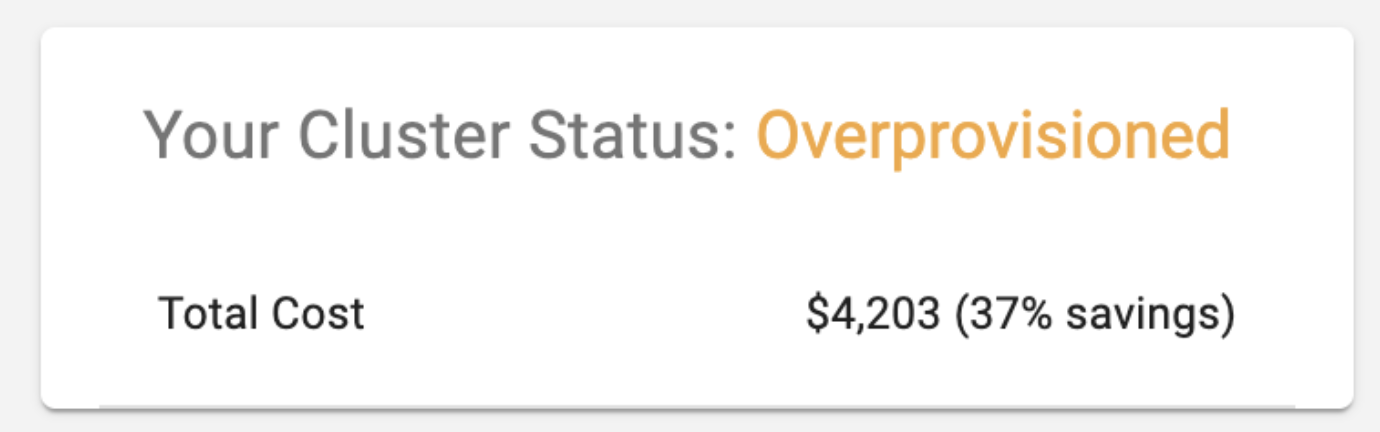
The Importance of Right-Sizing Kubernetes Clusters
Understanding the importance of right-sizing Kubernetes clusters is crucial in the complex landscape of Kubernetes. Oversized clusters lead to unnecessary expenses, as cluster resources are underutilized but still show up on your cloud bill. Conversely, undersized clusters can cause performance bottlenecks, leading to slow application performance and potential downtimes, which in turn can harm user experience and business operations. Right-sizing ensures that clusters are neither too large nor too small, but perfectly tailored to meet the specific needs of the applications they host. This balance is not just about cost optimization; it’s also about maximizing operational efficiency and ensuring reliability. By right-sizing Kubernetes clusters, organizations can achieve optimal resource management, maintain high performance, and avoid the pitfalls of over or under-provisioning, which are all key to a successful cloud-native strategy.
Kubecost’s Cluster Right-Sizing Recommendations
Managing Kubernetes clusters efficiently is a key concern for any organization looking to optimize costs and application performance. This is where Kubecost’s Cluster Right-Sizing Recommendations come in handy, offering a streamlined solution to ensure your clusters are configured in the most cost-effective manner possible.
Kubecost’s right-sizing tool is not just about providing recommendations; it’s about implementing them effectively. The tool distinguishes between two critical processes: viewing cluster recommendations and adopting them. This dual approach allows for a comprehensive understanding of your clusters’ needs before making any changes.
How it works
The tool generates context-aware cluster sizing recommendations after analyzing Kubernetes metrics on historical workloads and cloud billing data. As a user, you only need to provide the context of the cluster, i.e. whether it is being used for development, production, or high-availability workloads. We then recommend cluster configurations, which optimize for the respective balance of cost, simplicity, and performance/headroom. Because this solution is Kubernetes native, we consider the following when providing recommendations:
- Analysis of historical pod/container resource consumption to predict future requirements
- Consideration of both resource requests and usage
- Ensuring largest workloads can be scheduled successfully
- Accounting for DaemonSet/kube-system replication requirements for each node
- Allocating headroom based on cluster context, e.g. dev, prod, high availability
- Avoiding shared core machines for production/HA environments
Key features
Central to its functionality are two primary recommendation types: simple, which utilizes a single node type, and complex, employing multiple node types for greater optimization. These recommendations are presented alongside your current cluster setup, providing a clear comparative view of total cost, node count, and resource usage. Customization is a key aspect, with multiple dropdown menus allowing users to tailor the recommendations to their specific needs. Users can select individual clusters, define the time window for analyzing recent activity, and even view optimization inputs, like resource requirements determined by DaemonSets or the largest single Pod resource allocation. Importantly, Kubecost considers the unique requirements of different cluster contexts — whether it’s Production, Development, or High Availability — and offers recommendations accordingly. Additionally, the tool supports both x86 and ARM architectures, with current ARM support focused on AWS clusters. This combination of detailed, context-sensitive analysis and user-friendly customization makes Kubecost’s right-sizing feature an effective tool for efficient Kubernetes cluster management.
How to use
Kubecost’s Cluster Right-Sizing Recommendations tool is user-friendly and accessible, designed for quick and free installation via Helm or a flat manifest. Once Kubecost is set up, simply head to the ‘Savings’ section in the left navigation and select the ‘Right-size your cluster nodes’ panel to access the feature. Initially, the tool presents recommendations for a ‘development’ cluster context, but you have the flexibility to switch to other cluster types, such as ‘Production’ or ‘High Availability’, for more tailored advice. Users can also fine-tune their cluster right-sizing configurations by selecting specific clusters, adjusting the time window for recent activity analysis, and toggling optimization inputs to understand minimum node sizes based on cluster resources used by DaemonSets, the largest Pods, and other factors. For those looking to apply these recommendations, prerequisites include having a GKE/EKS/AWS Kops cluster and granting write access to Kubecost through the Cluster Controller. The adoption process is streamlined – select ‘Adopt recommendation’ and ‘Adopt’ to implement the suggested right-sizing, which typically takes about 10-30 minutes. Additionally, Kubecost offers a Continuous Cluster Right-Sizing option, accessible via the ‘Actions’ page, for ongoing optimization, making it a comprehensive tool for efficient cluster management.
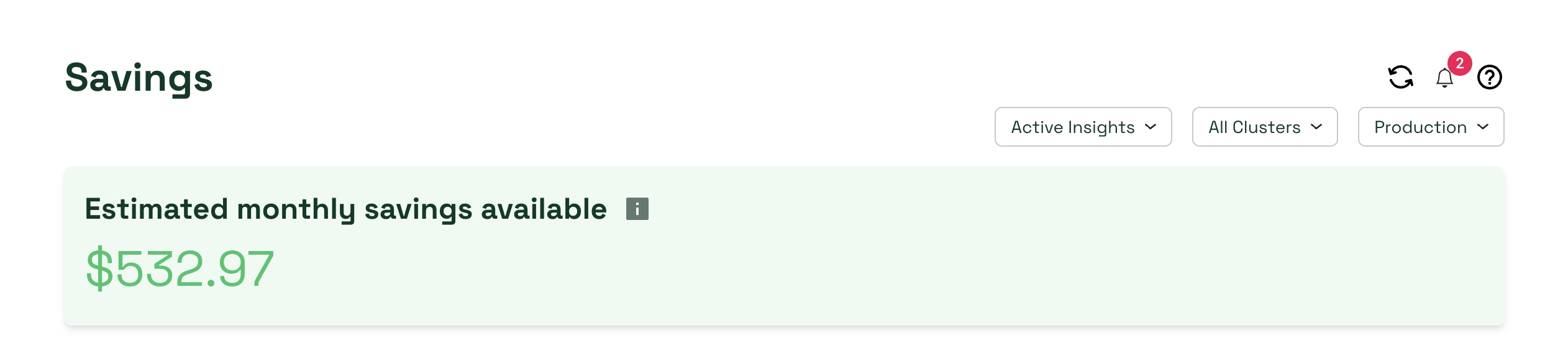
Note: no data is egressed from your cluster with this product and everything runs with your infrastructure.
Working Example
The following example presents two potential strategies in a Production cluster. There is a tradeoff between cost and complexity in this scenario. The simpler of the two configurations requires only two nodes, but the complex solution of four nodes offers an additional 3% savings per month by bin packing resources more efficiently than otherwise possible with only one node type. Advanced metrics are available directly in the UI to better understand the rationale for these recommendations.
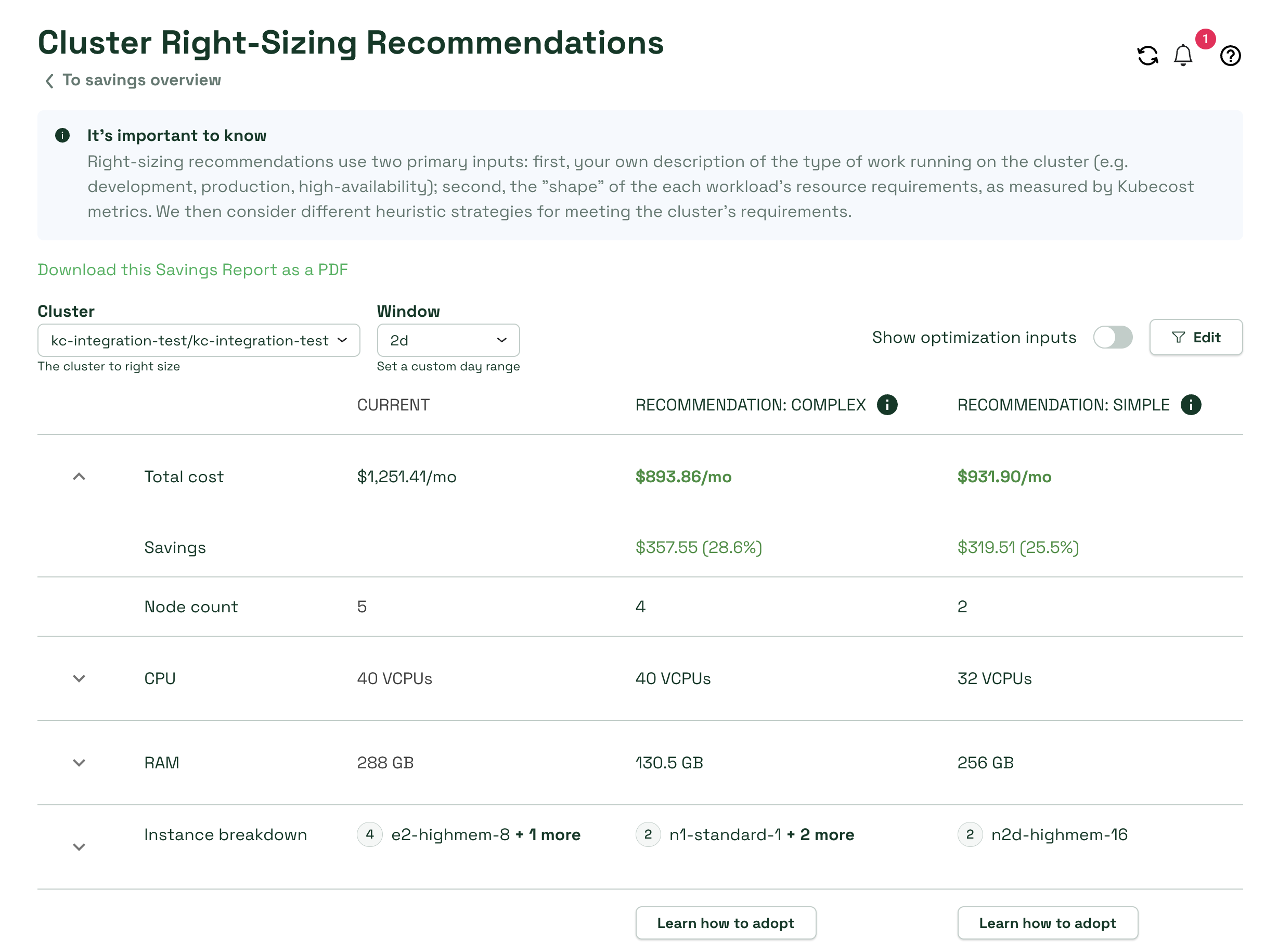
Our Approach to Cluster Sizing
To generate accurate recommendations, a potential cluster must be adequately-sized such that it is possible to schedule all workloads on the cluster. To assess this requirement, workloads scheduled as DaemonSets must appear on each node, making total resource allocation a function of node count. Furthermore, one large workload may not be able to fit on a fleet of small nodes, even if the aggregate amount of resources would appear adequate. We are able to use metrics generated by the core Kubecost allocation model (open source) to calculate nth-percentile total resource allocation over time, the percentage attributed to DaemonSets, and the largest single workload.
As a function of the cluster context, e.g. dev or production, we then analyze the shape of historical resource consumption and apply the appropriate headroom budget. Requirements for production clusters include a minimum of two nodes and a target resource utilization of 75%. Requirements for development clusters include a minimum of one node and a target resource utilization of 80%. Requirements for high-availability clusters include a minimum of three nodes and a target resource utilization of 65%.
Beyond these requirements, we apply a heuristic to manage the tradeoff between cost and complexity. For example, many teams would agree that, given the choice between saving 30% with a simple option and saving 31% with an utterly complex one, the simple option sounds more attractive. Therefore, we’ve chosen to start with two implementation strategies instead of one, hence the recommendations in the aforementioned examples.
The Limitations of Autoscaling in Cluster Sizing
You might be wondering why cluster sizing can not be solved by autoscaling. In the time we’ve spent helping teams of all kinds optimize their Kubernetes environments, we’ve found that cluster autoscaling, while useful, does not always resolve right-sizing concerns.
Autoscaling limitations
- Lack of Node Type Diversity: Autoscaling often relies on a single node type, which can lead to inefficient resource management. In contrast, Kubecost’s right-sizing tool can recommend multiple node types (complex recommendation), leading to more efficient resource allocation and cost savings.
- Over-Provisioning Risks: Autoscaling can result in over-provisioning, especially if the autoscaler’s node type doesn’t align well with the resource proportions of the workload. This can lead to increased costs without corresponding benefits in performance or reliability.
- Delayed Response to Demand Fluctuations: Autoscaling reacts to changes in demand, which can sometimes lead to delays in scaling up or down. This delay might cause performance issues or unnecessary cost accrual during periods of low usage.
- Limited Scope of Optimization: Autoscaling primarily focuses on responding to current demand, rather than analyzing historical data to predict and prepare for future needs. Kubecost’s tool, however, uses historical workload and cloud billing data for more comprehensive and forward-looking recommendations.
- Does Not Address Cluster Context: Traditional autoscaling does not consider the specific context of the cluster (e.g., development, production, high availability), which can be crucial for ensuring the right balance between cost, performance, and reliability.
Consider that autoscaling, even when it is working, does not allow for the possibility of adding different node pools to a cluster. It’s still easy, therefore, to end up over-provisioning if the autoscaler’s single node type is inappropriate for the resource proportions of the given workload. Over-provisioning by an autoscaler can be a painful experience, whereas using the cluster sizing recommendation puts the control and information in your hands to right-size your cluster when the time is right, without fear of runaway costs due to a single resource spike, memory leak, or ill-fitting node type.
Beyond Cluster Sizing
Expanding beyond the cluster sizing, comprehensive Kubernetes cost management encompasses a wider spectrum of tools and strategies to optimize spending and efficiency in a Kubernetes environment. Kubecost offers a variety of tools designed to provide real-time visibility and control over Kubernetes spending, including:
- Cost Allocation and Analysis: Break down costs by Kubernetes concepts like deployments, services, namespaces, and labels. This granular view enables teams to understand exactly where and how their resources are being spent, fostering more informed decision-making.
- Showback and Chargeback: Allocate costs accurately across different teams or departments. This feature is key for enterprises looking to distribute Kubernetes costs fairly and transparently.
- Resource Optimization Insights: Insights into resource optimization across the Kubernetes environment. We provide recommendations for reducing spend without sacrificing performance, to help organizations balance cost efficiency with operational effectiveness.
- Budget Alerts and Governance: Prevent cost overruns by incorporating alerts. Alerts notify teams of spending anomalies or when budgets are nearing their limits, ensuring that costs remain within expected boundaries.
- Multi-Cluster Visibility: For organizations operating multiple Kubernetes clusters, Kubecost offers a unified view of costs and usage across all clusters. This holistic perspective is vital for managing resources and costs at scale.
- Custom Reporting: Customize reports enable organizations to tailor their cost and usage data reports to meet specific needs, whether for internal review or compliance purposes.
Conclusion
Kubecost’s Cluster Right-Sizing Recommendations represent a vital tool in the realm of Kubernetes cost management, offering a balanced approach to optimizing infrastructure expenditure and operational efficiency. This tool goes beyond mere cost-cutting, providing intelligent, context-aware recommendations tailored to various workload demands. It effectively addresses the limitations of traditional autoscaling by incorporating a comprehensive analysis of historical data and cluster-specific contexts. Alongside our right-sizing capabilities, we offer an extensive suite of features for Kubernetes cost management, including cost allocation, resource optimization insights, and budget alerts, creating an essential tool for teams looking to streamline their Kubernetes operations and elevate their FinOps strategy.
About us
Kubecost offers real-time visibility and monitoring of Kubernetes costs, playing a crucial role in efficient cloud infrastructure management. Kubecost can run on any Kubernetes environment, including Azure Kubernetes Service (AKS), Google Kubernetes Engine (GKE), Amazon Kubernetes Service (AKS), and on-prem. With capabilities like multi-cluster visibility and custom reporting, we are tailored to meet the diverse needs of complex enterprises, making us an effective tool for effective Kubernetes cost management and optimization. To learn more, reach out via email (team@kubecost), Slack, or visit our website.
